How to Perform Object Detection using VIDIZMO Vision Indexer
The VIDIZMO Vision Indexer uses artificial intelligence to analyze videos, images, and documents in your Portal and identify visual elements and text. It can detect objects such as faces, people, vehicles, safety equipment, devices, and license plates, as well as extract text using Optical Character Recognition (OCR).
You can configure the Vision Indexer to run detections automatically on uploaded content or execute them on demand for both new and existing files. This flexibility allows you to choose between fully automated processing and manual control, depending on your operational and compliance requirements.
Once enabled, the Vision Indexer applies the selected detection types consistently across supported media formats, helping you surface insights, improve search accuracy, and support downstream actions such as redaction.
Prerequisites
- Ensure you’re in a group with feature permission to configure the VIDIZMO Vision Indexer and perform object detection. You also need permission for the individual AI features to use them. See: Enable Features in the VIDIZMO Portal.
- (Optional) To choose detections during upload, your portal must have Custom Upload enabled.. See: How to Custom Upload Media
- Ensure the VIDIZMO Vision Indexer is configured and enabled for the detection types you need. See: Configuring VIDIZMO Vision Indexer for Object Detection
Note: Keep your configuration focused. Select only the detection types you actually need to reduce processing time and false positives.
Performing Automatic Object Detection
When enabled, the VIDIZMO Vision Indexer automatically processes uploaded content based on the detection types you select in the application. This ensures that the specified visual elements are identified without manual intervention.
Automatic processing occurs when:
- Content is uploaded.
- Content is ingested.
- A copy is created.
- A VIDIZMO Live session is saved and published, see: Understanding Live Streaming in VIDIZMO.
Automatic Object Detection on Upload
Here’s how automatic detection works on upload.
- Select + Add New button.
- Select Upload Media.
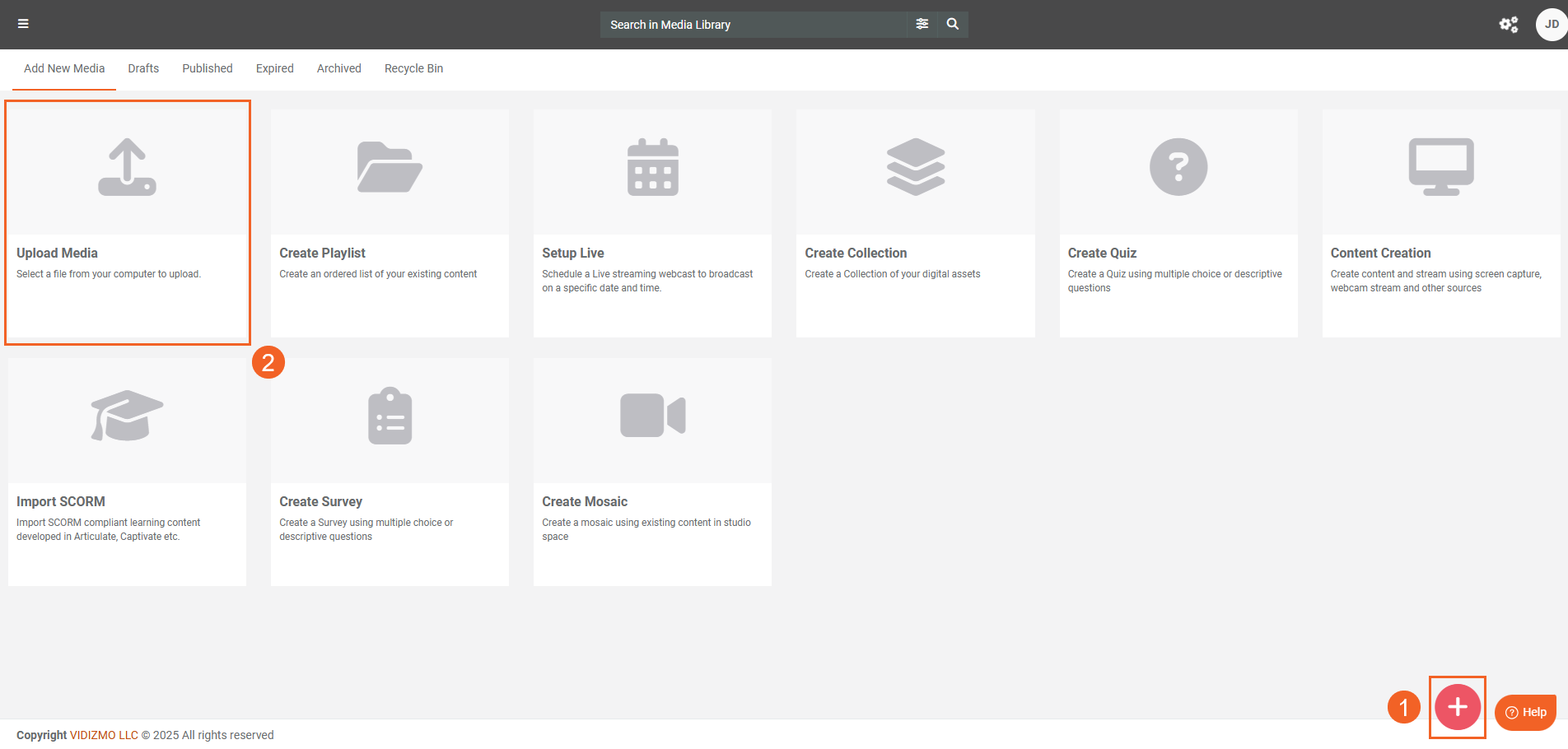
- Upload your file. The item undergoes Processing.
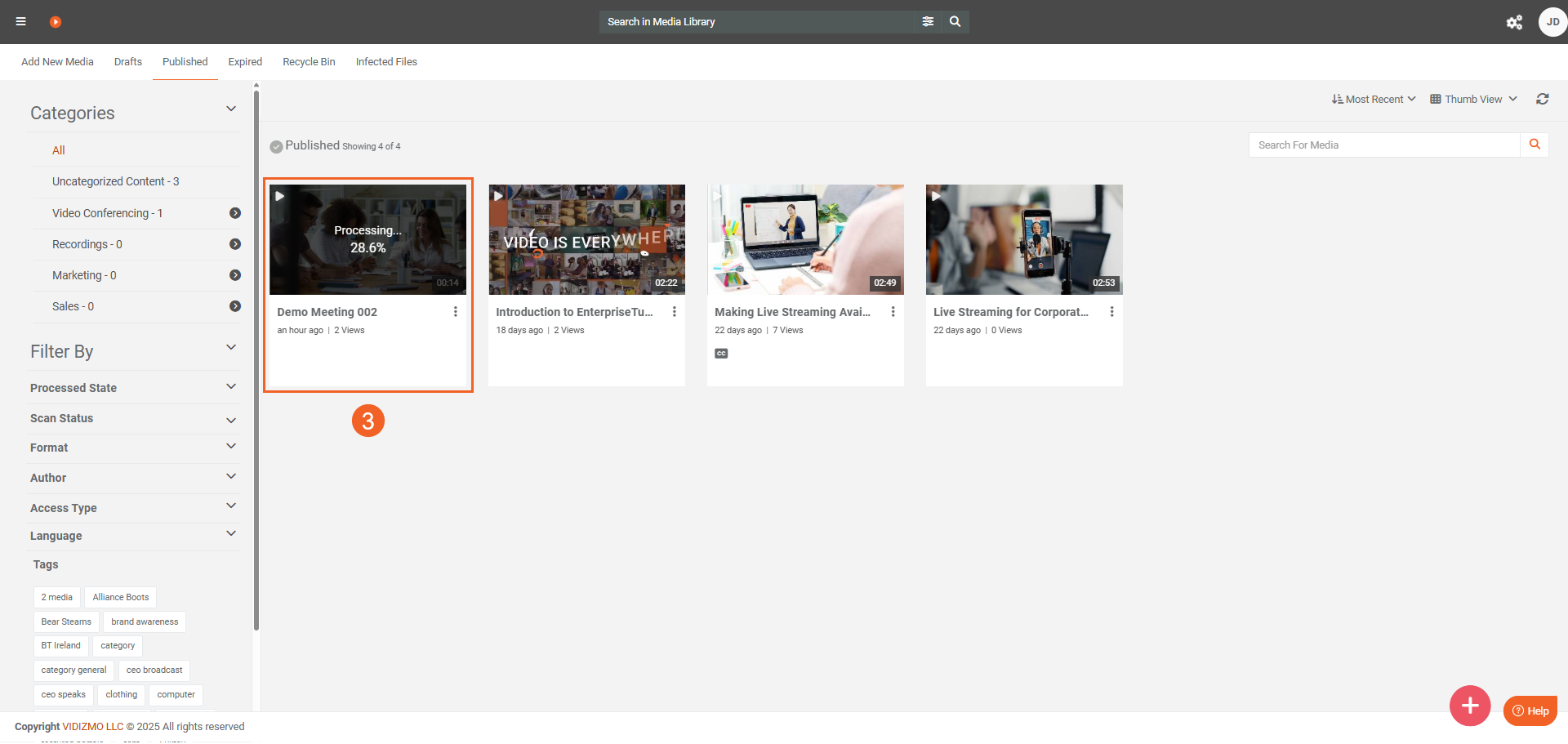
- After processing is complete, click the item to open its playback page.
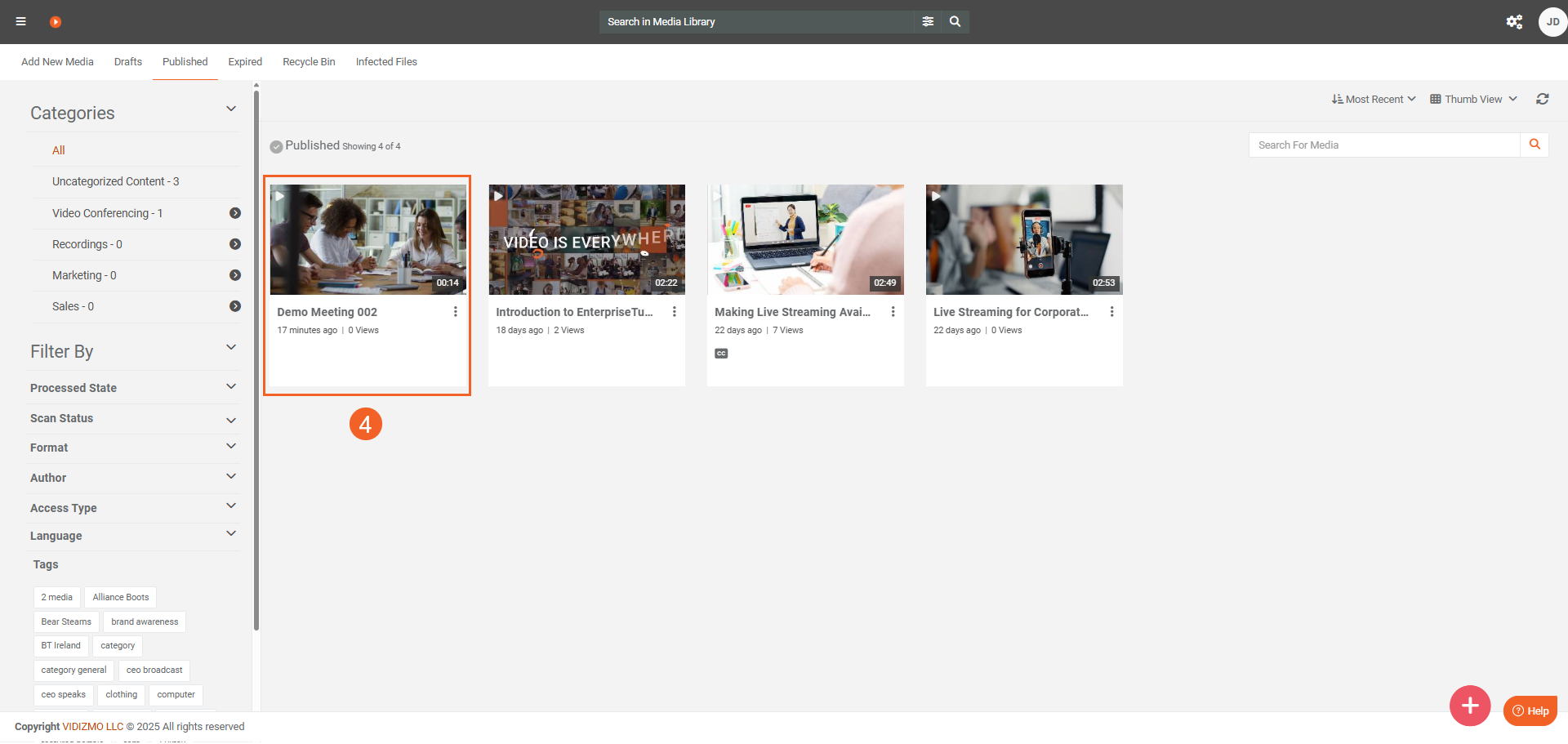
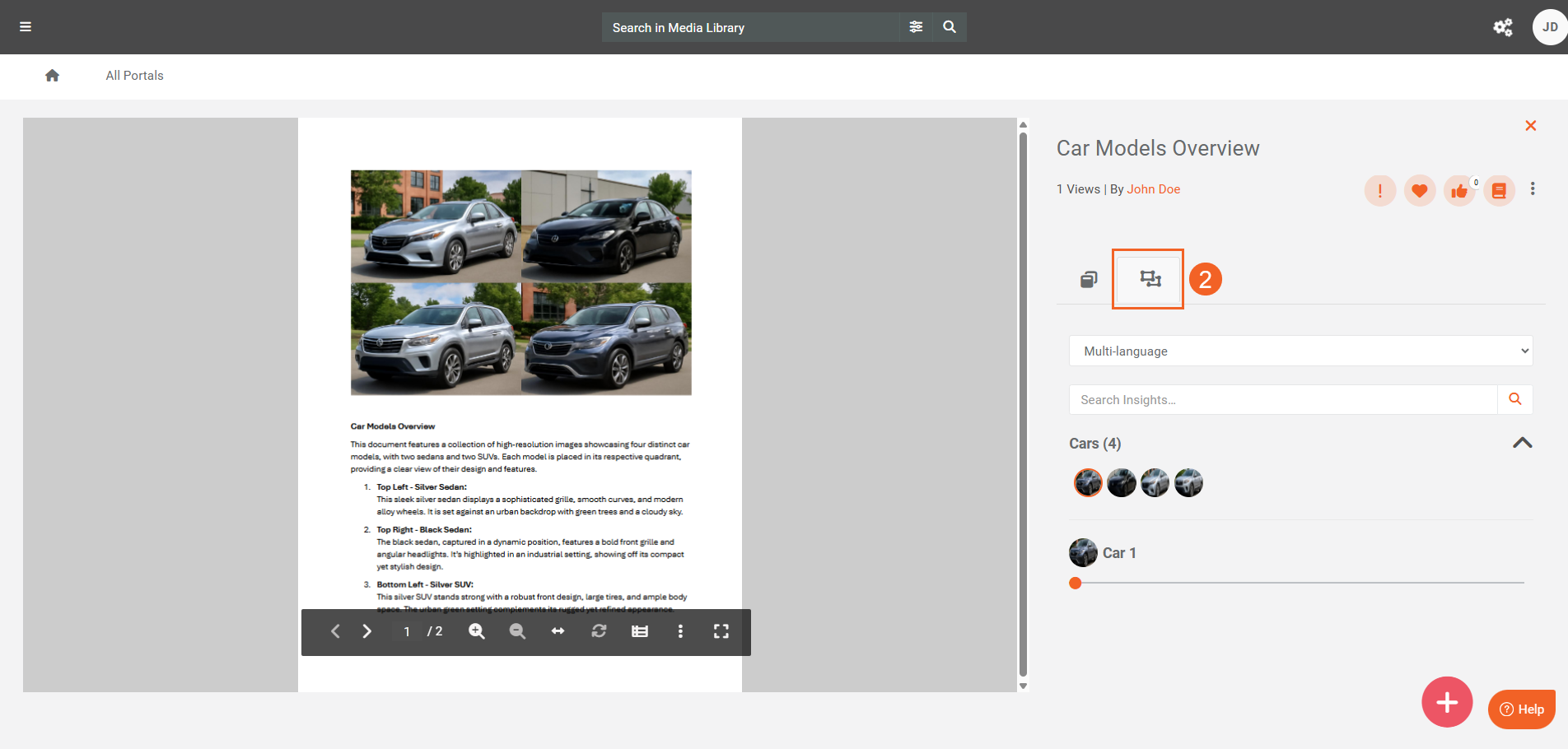
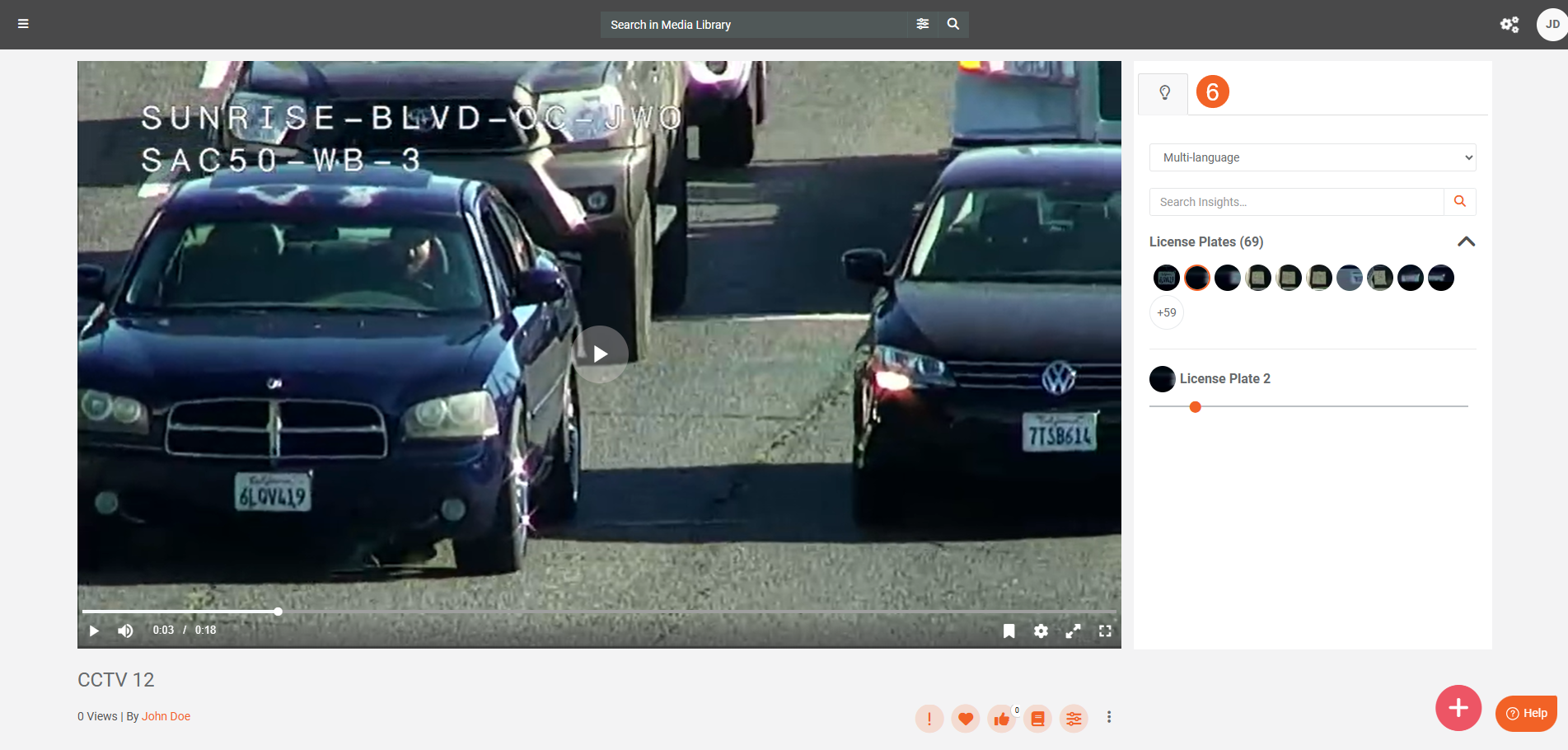
- Review detections in the Insights tab (for example, faces, vehicles, or license plates).
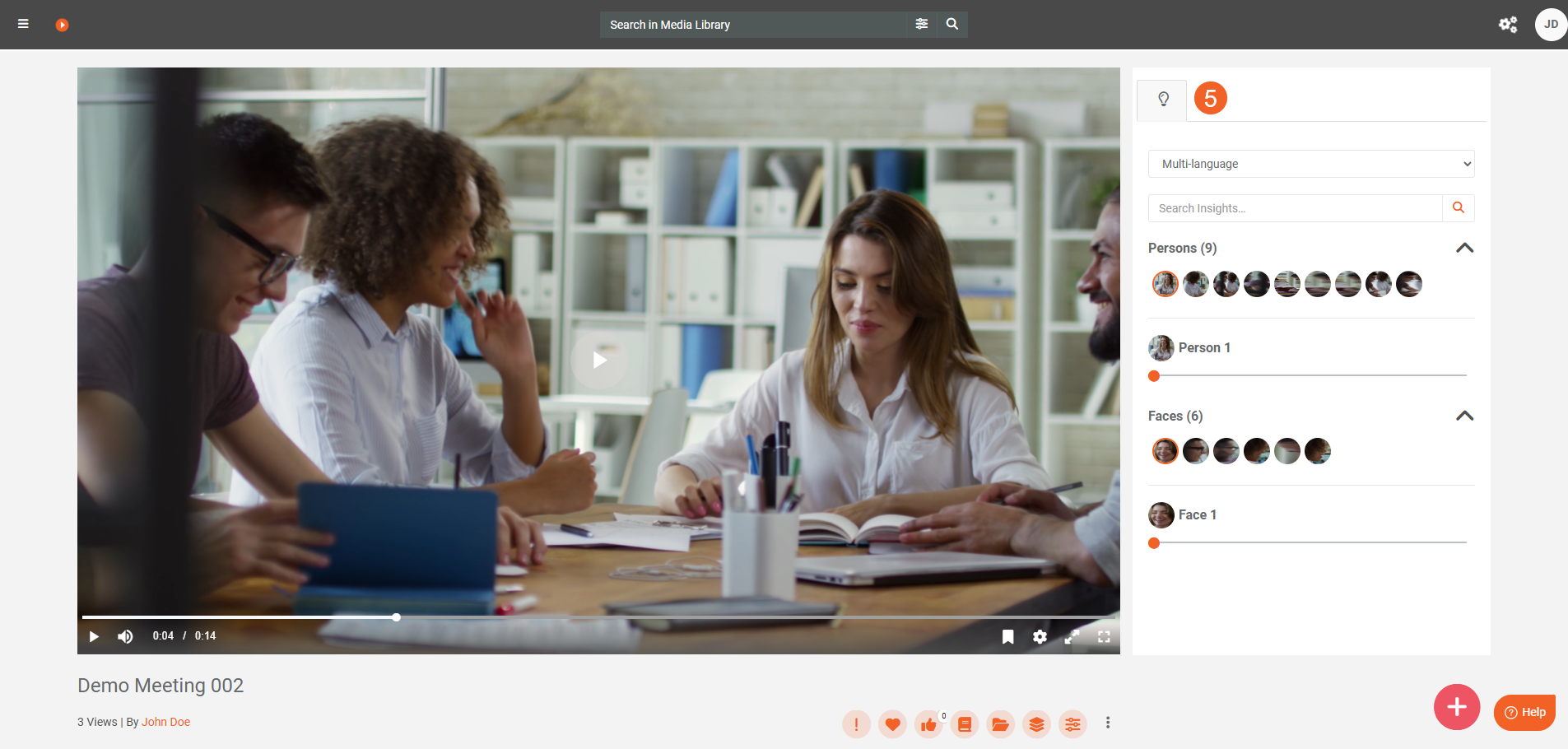
Note: The detections in the Insights tab depend on the detection types enabled in your VIDIZMO Vision Indexer configuration.
On-Demand Object Detection
Use on-demand detection when you want to control which content gets processed and which insights to generate.
On-Demand Object Detection from Custom Upload
When Custom Upload is enabled, you can select which AI detection types are applied to your content at the time of upload. Use the following steps to run object detection on demand.
-
Upload your content. Depending on your portal:
- EnterpriseTube: Go to the Process tab.
- DEMS/Redaction: Use Advanced Upload.
-
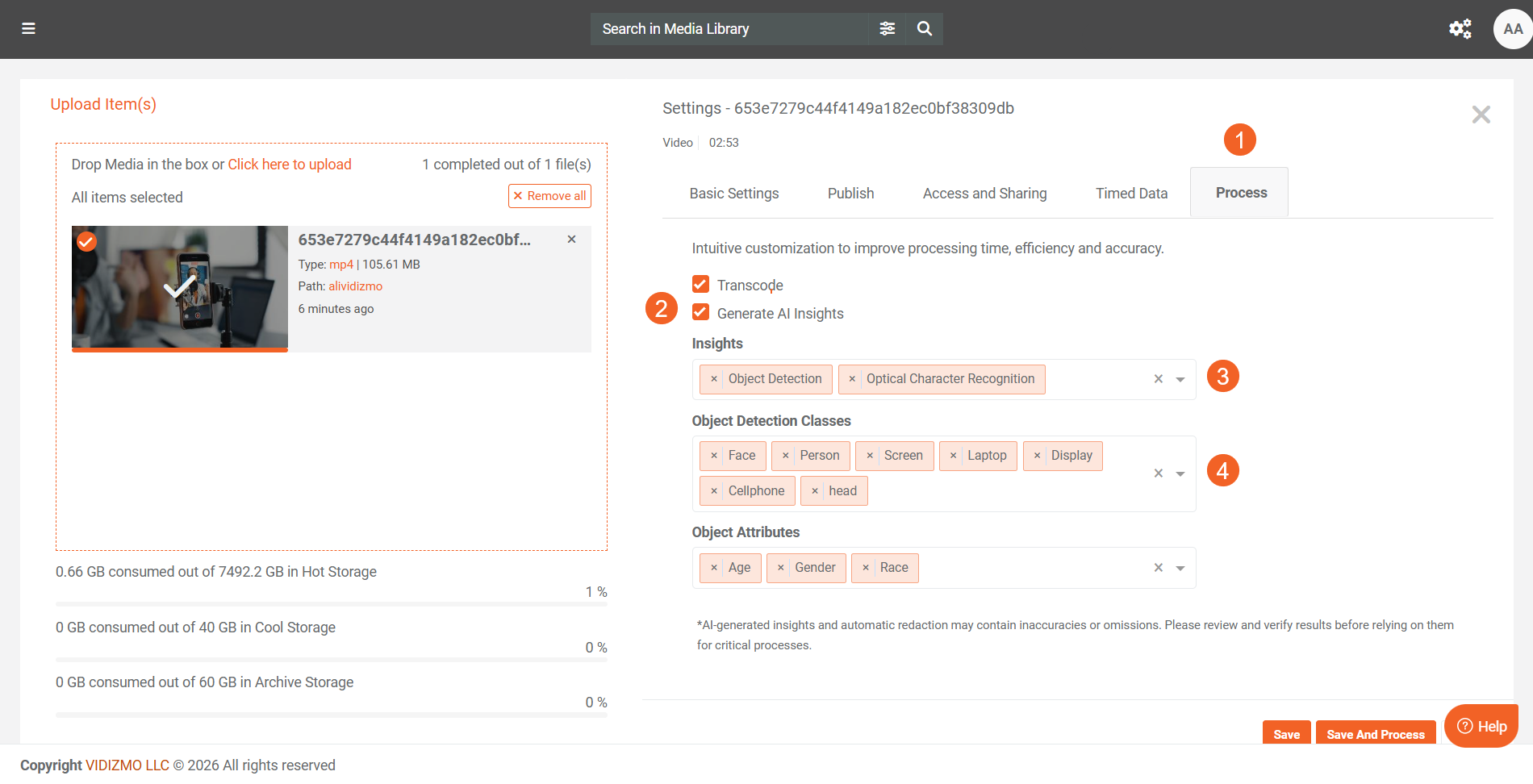
Select Generate AI Insights.
-
In the Insights section, select Object Detection, OCR, or both, as needed.
-
Under Object Detection Classes, choose the specific object types you want to detect (for example, License Plate, Text (OCR), Head).
-
Select Save or Save and Process to apply your selections and begin processing.
- After processing, play your content to see the detections in Insights.
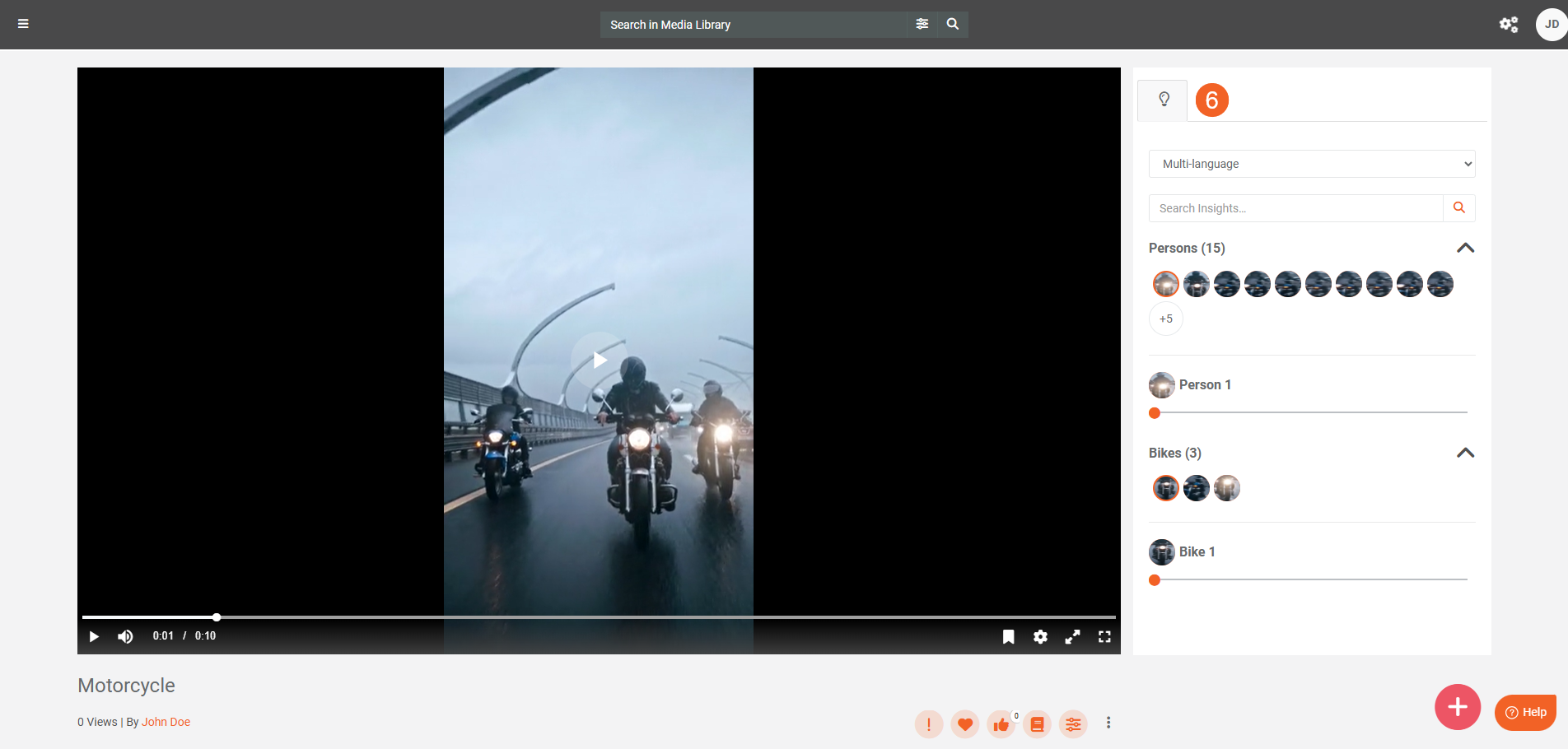
On-Demand Object Detection from Process Modal
For existing content already in your Portal, you can use the Process Modal to selectively perform object detection.
Detect from the Process Modal (existing content or bulk)
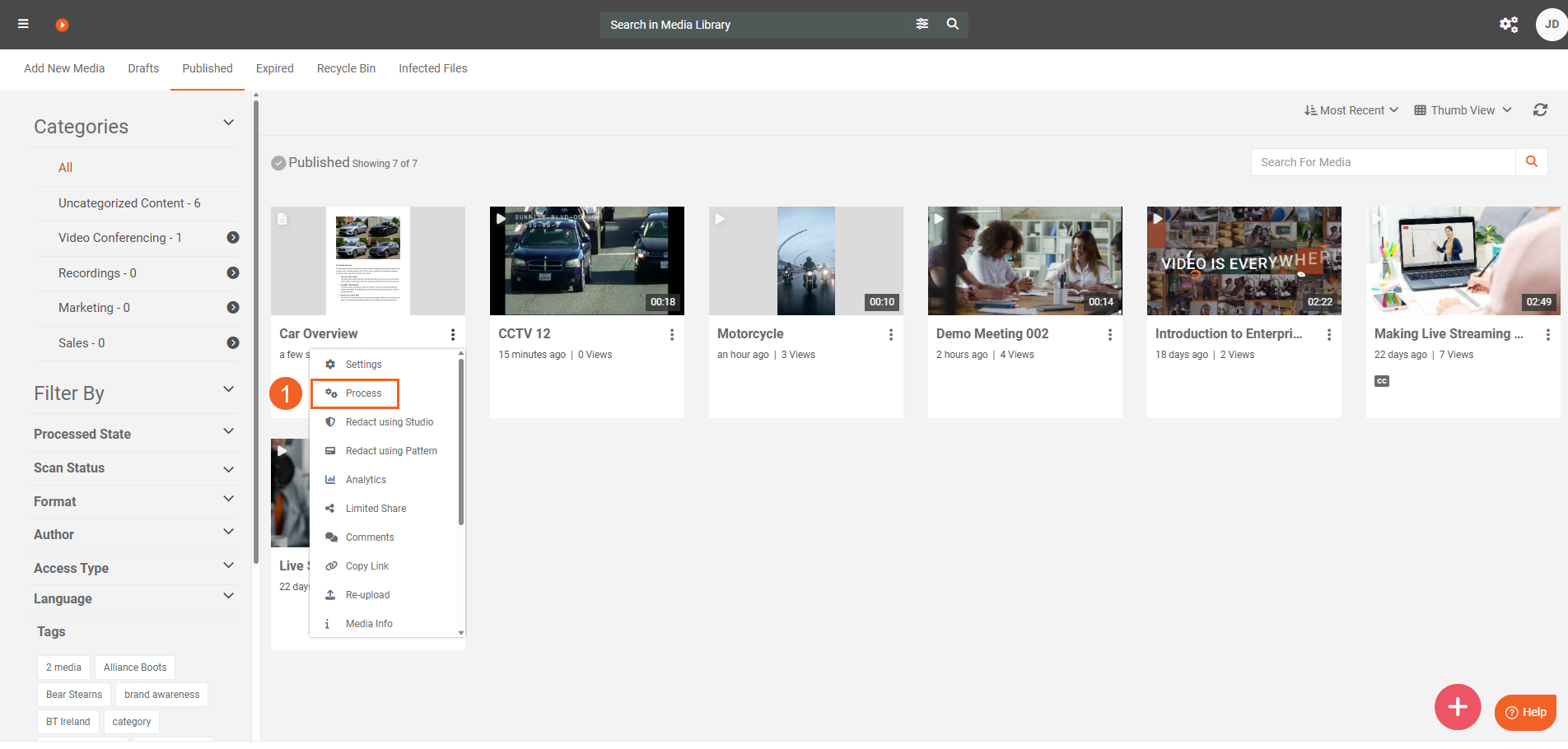
- For a single item, open the item menu (⋯) and select Process.
- For multiple items, select the items and choose Process from the header.
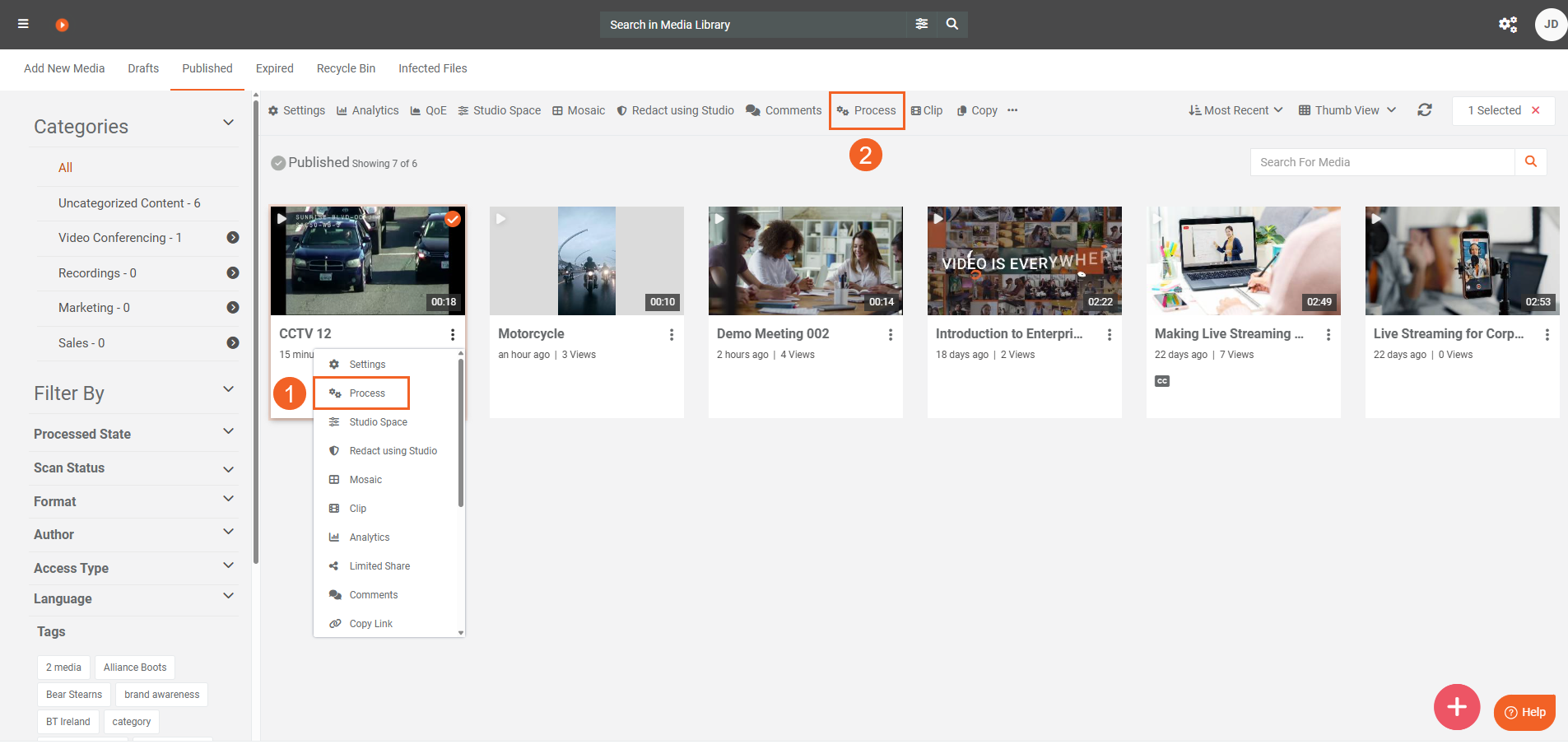
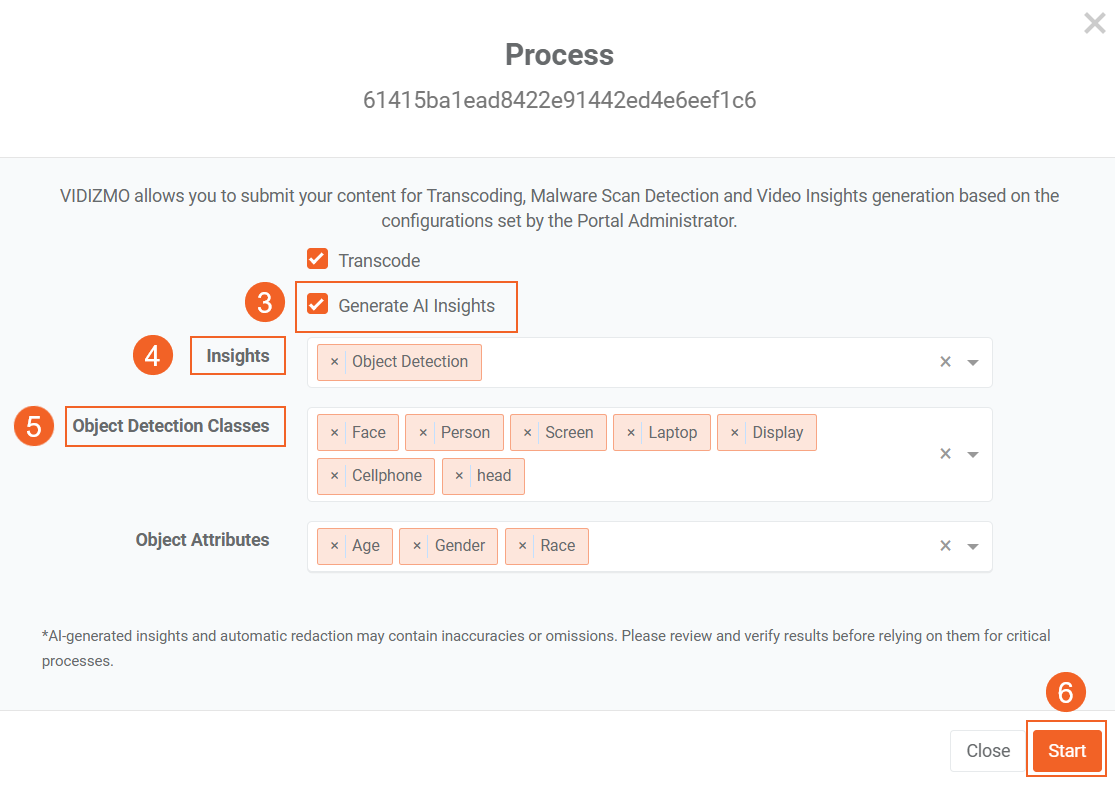
- In the Process modal, select Generate AI Insights.
- In Insights, select Object Detection.
- In Object Detection Classes, add the object types you want the system to detect. For objects that support additional attributes, select the relevant options in the field that appears next.
- Select Start.
- When processing is complete, open each item and see detections in Insights.
Object Detection in Documents
In the VIDIZMO Vision Indexer configuration, make sure the following are selected:
- Select Document in Media/Evidence Type(s)
- The desired Detection Types are selected (Face Detection, or Vehicle Detection)
To process documents:
- Upload a document containing these objects for automatic processing or use the Process Modal for on-demand processing.
- After processing, open the document and view the detected objects in the Insights tab. You can also search for and navigate to the page where these objects are present by clicking the object’s thumbnail.