Understanding VIDIZMO OCR
Optical Character Recognition (OCR) in VIDIZMO allows you to detect and extract text from images, videos, and documents within your Portal, improving their searchability and making them more accessible. This feature can be configured via the VIDIZMO Vision Indexer, which uses an OCR engine to analyze and extract characters from video frames, document pages, and images.
The application detects and converts the text within your content into searchable metadata, significantly enhancing discoverability. The OCR engine in VIDIZMO's Vision Indexer also supports multiple languages and can accurately extract text from multilingual content.
Additionally, VIDIZMO provides OCR-based redaction capabilities via its Studio Space, enabling users to redact sensitive information such as personally identifiable information (PII) or financial data from their content. The redacted content remains fully functional and accessible; users can view, search, and interact with it without losing the core context, even after sensitive information has been redacted.
VIDIZMO OCR Process
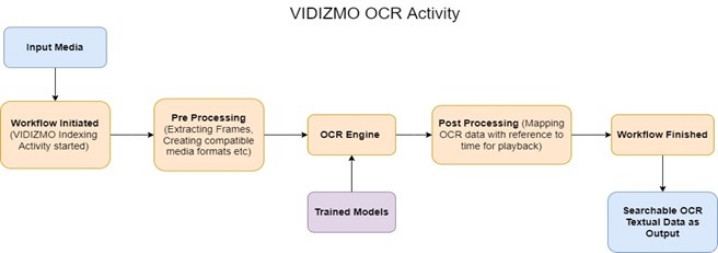
VIDIZMO's OCR workflow involves multiple phases to extract text from videos, images, and documents, making the content searchable, navigable, and redactable.
Preprocessing Phase
-
The Indexer extracts frames from videos and pages from documents to prepare them for OCR analysis. Images are sent directly to the OCR engine without segmentation.
-
For videos, frames are extracted at specific time intervals for processing efficiency.
Processing Phase
-
The OCR engine processes the extracted frames or pages, generating OCR objects (recognized characters or text).
-
These OCR objects include the text and spatial coordinates within the video frame or document page.
Post-processing Phase
-
The OCR data is mapped back to the original content with reference to time for videos and line number for documents, ensuring that OCR detections align precisely with playback moments or document pages.
-
This mapping allows users to jump directly to the exact timestamp in videos or the exact page in documents where detected text appears. Storage and Usage
Storage and Usage
All OCR-generated data is stored as metadata within the VIDIZMO Portal database. This metadata supports various functionalities:
- Portal-wide Search: Enabling users to find content using Portal search.
- Playback search: Precise navigation to relevant information during playback.
- Redaction: Providing selectable OCR objects to remove in Studio Space
OCR For Videos
VIDIZMO performs OCR on videos by extracting frames at regular intervals, creating segments, and analyzing each frame for detectable text or characters.
- During preprocessing, the Vision Indexer extracts the frames from your video and creates segments for these frames, grouping them based on time intervals to organize OCR processing efficiently.
- The OCR engine processes the extracted frames, generating OCR objects (recognized text region).
- During post-processing, the OCR data is mapped back to video segments according to their timestamps. This allows users to search for specific text and navigate directly to the moment of its appearance during playback.
- The processing time varies with video duration and quality, as longer or higher-quality videos have more frames to process.
OCR For Images
When OCR is performed on images, the image file is sent directly to the OCR engine.
- The engine extracts any text present and generates OCR metadata quickly since there is no need for multi-frame processing.
- The OCR metadata allows images to be searchable on the Portal and enables users to perform redaction using Studio Space.
OCR For Document
VIDIZMO's OCR engine extracts text from documents, enabling search and navigation whether the documents are editable or not.
Editable vs Non-Editable Documents
-
Editable documents are those where text can be selected, copied, and searched directly (e.g., Word documents, searchable PDFs).
-
Non-editable documents are typically scanned images or PDFs where the text is part of the image itself, meaning the text cannot be selected or searched because it is stored as pixels rather than actual text. These are often called scanned or image-based documents.
OCR Processing for Documents
- For non-editable documents, VIDIZMO creates an image copy of each page solely for OCR processing.
- The original document remains non-editable even after OCR; the image copy is only used to extract text and generate metadata.
- The OCR engine analyzes each page image line by line, extracting text and storing spatial coordinates to map text accurately within pages.
- Document OCR data is segmented based on lines, enabling precise mapping of OCR data back to the document during post-processing.
- This Enables searchability of text within scanned or non-editable documents that were previously unsearchable.
- OCR generation also aids in the redaction of sensitive information, even on non-editable documents; refer to How to Perform Document Redaction in VIDIZMO for more.
OCR-Based Redactions
VIDIZMO allows users to redact text identified through Optical Character Recognition (OCR) in their videos, images, and documents. If you have feature permissions for the Redaction or Bulk Redaction features, you can utilize VIDIZMO's Studio Space to redact the OCR text detected in your content. This redaction capability ensures that any sensitive or private information extracted by OCR is concealed or removed to align with your specific use case. Using Studio Space, users can accurately select and redact sensitive data, such as personally identifiable information (PII), contact details, license plate numbers, or identification numbers from their content.
When you process your content to generate OCR data, that information is used to display the detections when you open your processed content in Studio Space. The detected objects obtained from the OCR data are clearly labeled and selectable. Users can perform the redaction process by selecting the relevant detections and processing them to produce a redacted version of the original content.
To learn more about redaction in Studio Space, see Redaction using Studio Space: A Comprehensive Walkthrough.
Searching OCR Data
OCR-generated metadata enhances content discoverability on your VIDIZMO Portal by making text within your content searchable. You can search for OCR content using the Portal search (from pages like the Library or Homepage) and search for OCR-based data within your content during playback.
Searching OCR-Generated Content Using Portal Search
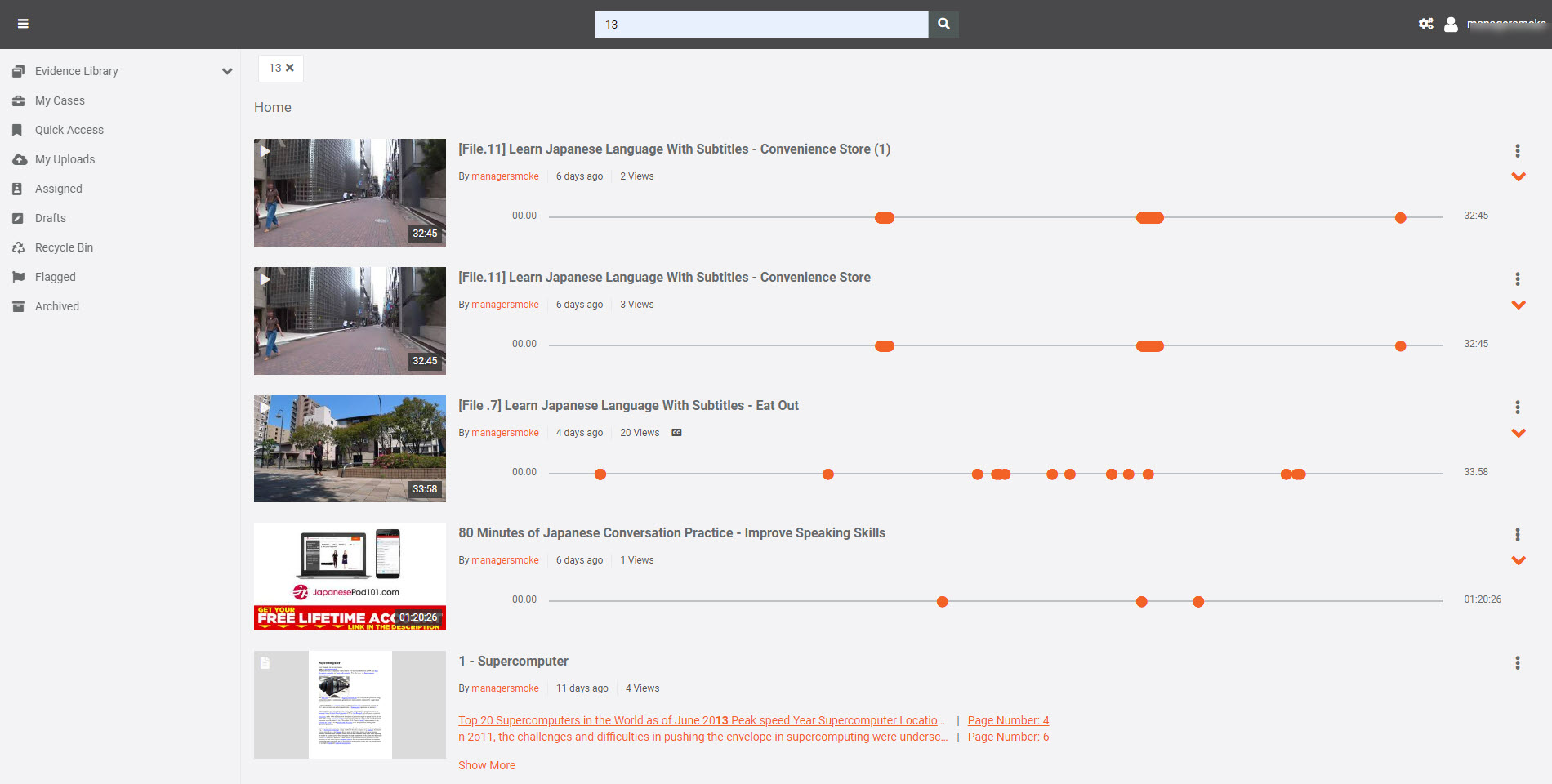
Your VIDIZMO Portal consists of a global search feature that allows you to search for content. You can also use search functionality to find content containing text detected through OCR across your entire Portal library, including videos, images, and documents.
-
When you enter a keyword into the Portal's global search bar, the system searches through all content metadata, including the text extracted by OCR.
-
The items will be displayed in the search results if the keyword matches any OCR-detected text within your videos, images, or documents.
-
The results list also shows all instances where the keyword appears, helping you locate every occurrence of the searched text (detected by OCR) across your content.
-
By selecting a specific search result, you are taken directly to that particular media file and the exact moment or page where the keyword was detected, streamlining your access to relevant information.
For comprehensive details on search in VIDIZMO, refer to Understanding Search in VIDIZMO
Searching OCR-Generated Content from Playback
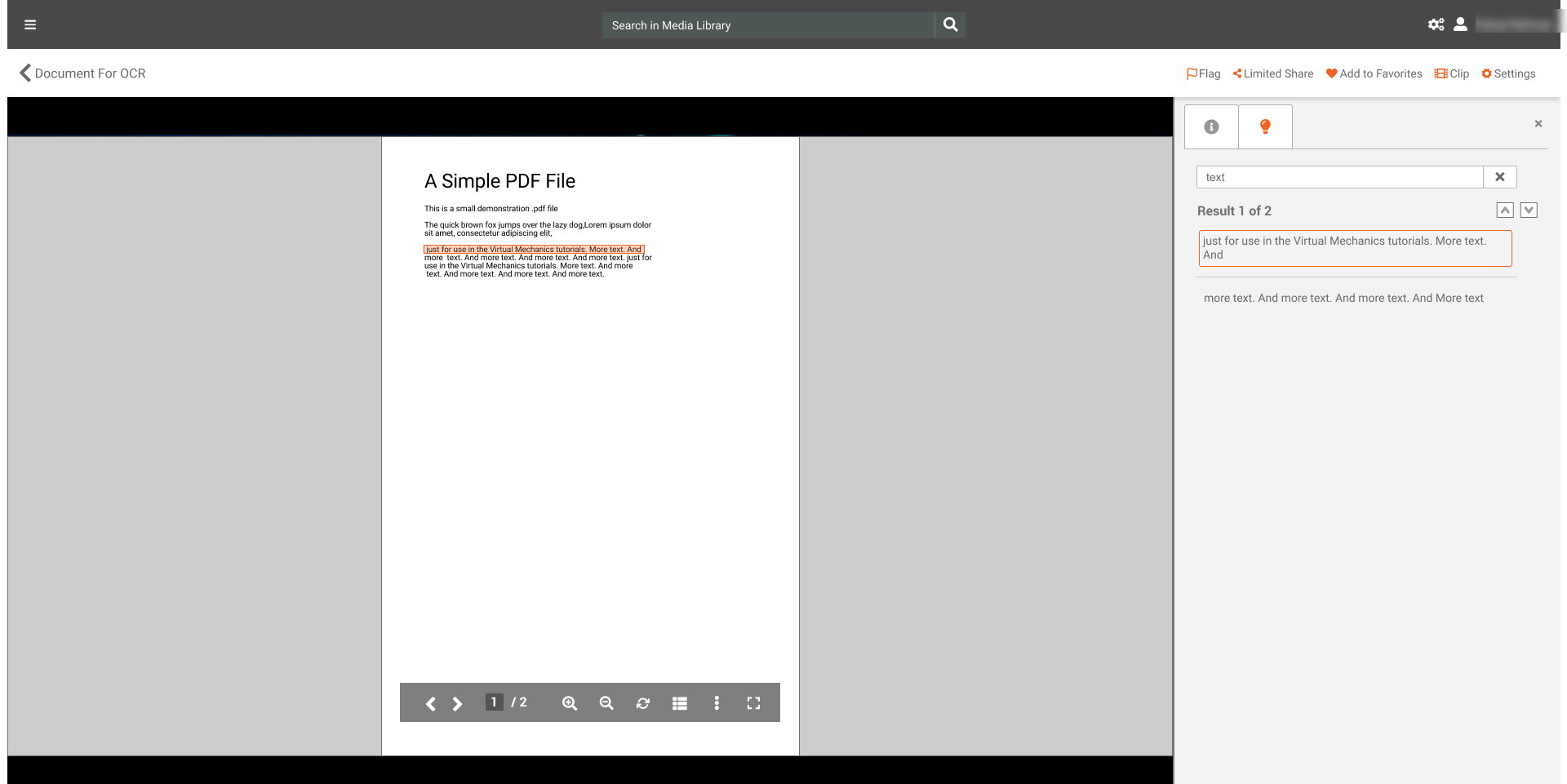
In addition to global search, VIDIZMO provides a dedicated search feature on the playback page for content that has undergone OCR processing.
-
While watching a video or browsing a document, users can enter keywords into a search bar available on the playback page.
-
The search results matching the keyword are displayed on the playback page highlight. The results include every instance where the searched text appears in your content. This enables users to view all occurrences of the text or characters they are searching for without manually scanning the entire content.
-
Selecting a highlighted search result instantly navigates the user to the exact timestamp in a video or page in a document where the text is found.
-
This seamless navigation lets users quickly access relevant moments, sections, or information in their content, saving time and effort.
Supported Languages
The OCR engine used by the Vision Indexer enables you to generate OCR objects in multiple languages, allowing you to manage the search or redaction for multilingual content on your Portal. This OCR engine utilizes several trained AI models that perform character recognition in various languages. You can select a specific language in the Vision Indexer's settings to perform character recognition and extract text in that language. By default, the OCR engine supports English.
Below is a list of some of the languages supported by the VIDIZMO OCR Engine
Albanian
Bosnian
Croatian
Czech
Danish
Dutch
English
Estonian
French
German
Hungarian
Icelandic
Indonesian
Irish
Italian
Latvian
Lithuanian
Maltese
Maori
Norwegian
Occitan
Polish
Portuguese
Romanian
Serbian (Latin)
Slovak
Slovenian
Spanish
Swedish
Tagalog
Turkish
Vietnamese
Welsh
Sindhi
Urdu
Arabic
Read Next
- Understanding Document Processing
- Understanding OCR (Optical Character Recognition) Apps in VIDIZMO
- How to Perform OCR using VIDIZMO Indexer
- Understanding Media Types and Formats