AI Content Processing in VIDIZMO
VIDIZMO AI content processing enables organizations to automatically analyze, enrich, and manage multimedia content uploaded to the VIDIZMO portal. The platform applies a combination of machine learning, computer vision, speech processing, and large language models (LLMs) to video, audio, image, and document assets.
The system is designed for scalable, modular processing, where independent AI pipelines execute in parallel and dependent pipelines execute sequentially based on data availability. This architecture allows VIDIZMO to efficiently process large volumes of unstructured content while maintaining accuracy, compliance, and extensibility.
VIDIZMO AI Content Processing Architecture
VIDIZMO AI content processing is orchestrated through two core indexing components:
-
VIDIZMO Vision Indexer responsible for visual intelligence
-
VIDIZMO Indexer responsible for audio, text, and language intelligence
Each indexer coordinates multiple specialized AI services. These services generate AI artifacts such as transcripts, captions, object detection, summaries, chapters, translations, and redacted renditions.
VIDIZMO Vision Indexer
The VIDIZMO Vision Indexer provides visual intelligence for video, image, and document content. It analyzes visual frames and extracted images to generate structured metadata for search, security, and compliance use cases.
Key capabilities include:
-
Object Detection across multiple classes:
- Face and person detection, with attribute detection for faces (age, gender, and race)
- Vehicle detection (car, bus, bike, truck, train, boat, airplane) and license plate recognition
- Weapon detection (guns and knives)
- Device detection (screens, laptops, cellphones, displays)
- Signature and street sign detection
-
Optical Character Recognition (OCR)
Visual insights produced by the Vision Indexer are consumed by redaction workflows, search indexing, summarization, and translation.
VIDIZMO Indexer
The VIDIZMO Indexer (formerly known as VIDIZMO Speech and Text Analyzer) is dedicated to speech and text analysis across video, audio, image, and document content.
It provides:
-
Speech-to-text transcription
-
Automatic language detection and translation
-
Personally identifiable information (PII) detection and redaction
-
Automatic summarization and chapter generation
The VIDIZMO Indexer converts unstructured spoken and written content into searchable, time-aligned text artifacts, enabling accessibility, compliance enforcement, and semantic understanding.
AI Features in VIDIZMO
VIDIZMO provides multiple AI features that can be applied to different content types. The availability of each feature depends on whether you are using VIDIZMO Vision Indexer, VIDIZMO Indexer, or both.
Supported AI Features by Content Type
| AI Feature | Audio | Video | Document | Image |
|---|---|---|---|---|
| Transcription | ✔ | ✔ | — | — |
| Audio Analysis | ✔ | ✔ | — | — |
| Translation | ✔ | ✔ | ✔ | ✔ |
| Object Detection | — | ✔ | ✔ | ✔ |
| OCR | — | ✔ | ✔ | ✔ |
| Summarization | ✔ | ✔ | ✔ | — |
| Automatic Chaptering | ✔ | ✔ | — | — |
| PII Detection and Redaction | ✔ | ✔ | ✔ | ✔ |
| Keyword Redaction (Regex-based) | ✔ | ✔ | ✔ | ✔ |
How AI Content Processing Works in VIDIZMO
When content is uploaded to the VIDIZMO portal, the system identifies the content type and determines which AI processing workflows to execute based on configuration and enabled features.
Key execution characteristics:
-
AI workflows execute automatically on upload or can be triggered on demand, as configured by the user.
-
Independent workflows run in parallel to minimize processing time.
-
Dependent workflows wait for prerequisite artifacts (for example, audio summarization requires transcription, video summarization requires video description, and document summarization requires selectable text).
Generated artifacts are persisted and reused by downstream features.
This modular execution approach maximizes scalability while ensuring consistent AI enrichment across content types.
AI Content Processing Workflow in VIDIZMO
The following sections describe the major processing workflow represented in the architecture diagram, including foundational content processing stages that prepare media for AI analysis.
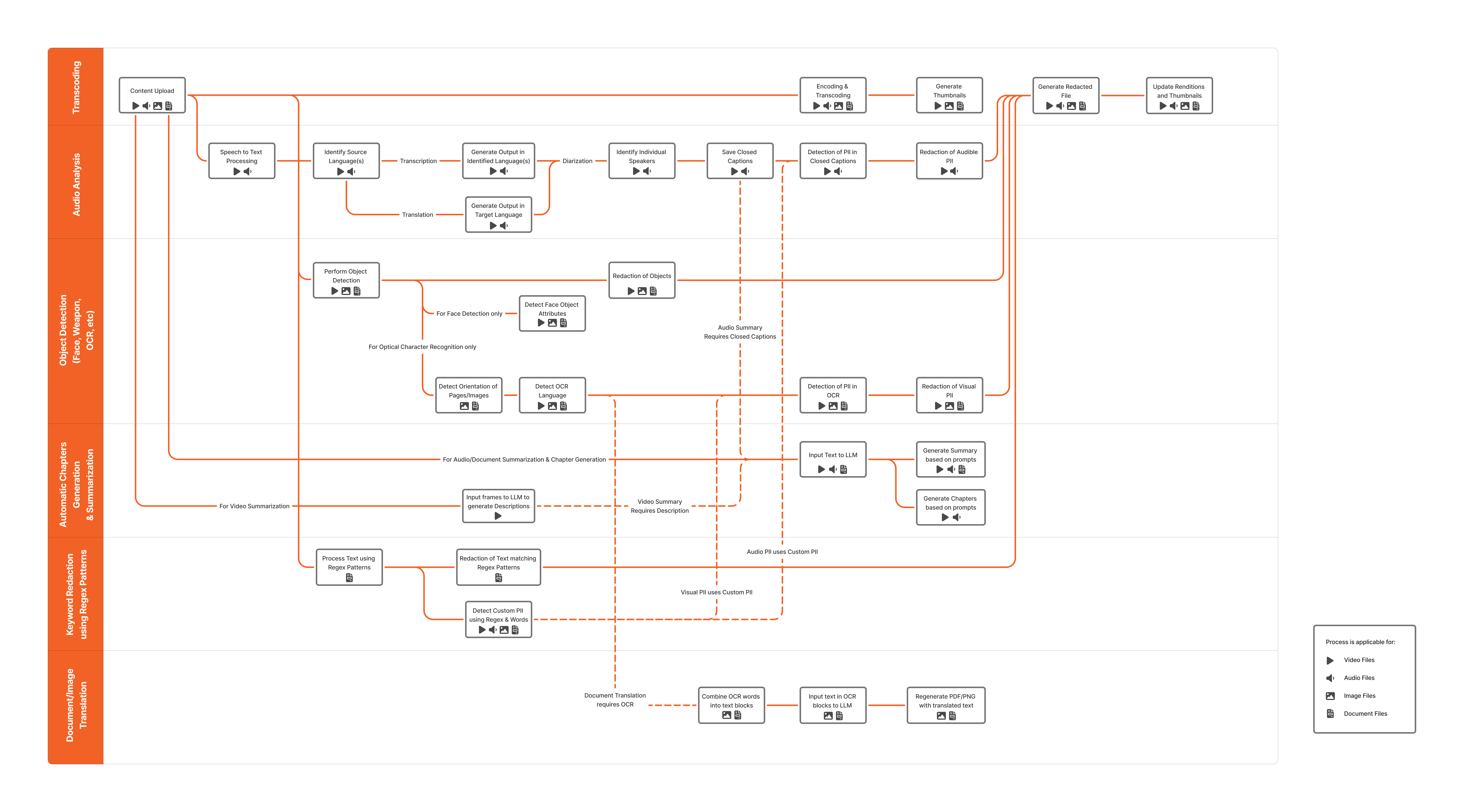
Transcoding
Content Upload Handles ingestion of video, audio, image, and document files into the VIDIZMO platform. Supports multiple industry-standard formats and validates compatibility for downstream processing.
Encoding & Transcoding VIDIZMO also allows to define encoding profiles against any transcoder of their choice. These encoding profiles primarily represent output format configurations for media files and determine how video and audio assets are encoded, packaged, and delivered.
During encoding and transcoding, media files are converted into standardized streaming formats and multiple bitrate renditions to ensure smooth playback across devices, browsers, and network conditions.
Generate Thumbnails
Once transcoding is complete, representative frames are extracted from video content to generate thumbnails that support preview, navigation, and discovery within the portal.
Generate Redacted File
If redaction workflows are enabled, VIDIZMO generates redacted renditions of the content with sensitive audio or visual information removed based on selected object classes, detected PII, or OCR text.
Update Renditions and Thumbnails
All generated renditions, thumbnails, and redacted versions are synchronized and published, making them immediately available for playback, indexing, and AI-driven enrichment.
Audio Analysis
Speech-to-Text Processing Converts spoken content in videos and audio files into time-coded text transcripts.
Identify Source Language(s) Automatically detects the dominant and segment-level spoken languages in the audio track. This enables accurate transcription for multilingual content.
Transcription Generates structured transcript output synchronized with timestamps.
Diarization (Identify Individual Speakers) Identifies and separates individual speakers within the audio stream, assigning speaker labels to transcript segments.
Save Closed Captions Produces closed caption files (VTT, SRT) for accessibility and playback compatibility.
Detection of PII in Closed Captions: Analyzes transcript text to identify personally identifiable information.
Redaction of Audible PII: Generates redacted audio renditions by masking or removing sensitive spoken content.
Translation Generates translated captions and transcripts for audio and video content in one or more target languages while preserving timestamps, speaker segmentation, and structure.
Object Detection and OCR
The Vision Indexer executes multiple detection tasks in parallel for optimal performance. Object Detection, Face Detection, and OCR run independently and do not depend on each other.
Perform Object Detection Detects objects appearing in video frames, including people, vehicles, weapons (guns and knives), and other configured object categories.
Redaction of Objects For detected objects, VIDIZMO generates bounding boxes and timestamps with start, end, and confidence scores that indicate the reliability of each detection. These detections can be directly consumed by redaction workflows, allowing sensitive visual elements to be masked or removed from the content while preserving non-sensitive regions.
Face Detection Detects facial features and groups faces across video frames. VIDIZMO also analyzes images or video frames to extract facial attributes such as age, gender, and race. Attribute prediction is performed only on detected faces and is supported for both static images and video content.
Each detected face includes associated metadata such as bounding box coordinates, confidence scores, and attribute predictions. Detected faces and their attributes can also be reprocessed by redaction, allowing faces to be blurred or removed based on the configured settings.
OCR (Optical Character Recognition) Extracts text from images, video frames, and scanned documents.
Detect Orientation of Pages/Images Corrects alignment to improve OCR accuracy.
Detect OCR Language Identifies the language of extracted text to enable accurate indexing and translation.
Detection of PII in OCR Identifies sensitive textual or visual information in OCR output.
Redaction of Visual PII Masks or removes sensitive visual content.
Automatic Chapter Generation and Summarization
VIDIZMO uses LLMs to generate summaries and chapter markers for audio, video, and document content.
Audio Summarization Generates concise summaries by analyzing transcripts. Transcription must be completed before audio summarization can run.
Video Summarization Generates video summaries by first analyzing video frames to produce visual descriptions, then processing those descriptions through LLMs. For combined audio and video summarization, both video description and transcription must be completed first.
Document Summarization Generates summaries by analyzing document text. Documents must contain selectable text for summarization to work.
Chapter Generation Generates chapter markers and titles based on transcription output, enabling structured navigation within audio and video content.
Keyword Redaction using Regex Patterns
In addition to AI-based PII detection, VIDIZMO supports custom regex-based keyword redaction. This allows organizations to define their own patterns for detecting sensitive information specific to their use case.
Audio PII Redaction Applies custom regex-based patterns to transcripts to detect and redact sensitive keywords. This works alongside AI-based PII detection to provide comprehensive coverage.
Visual and Textual PII Redaction Applies regex and keyword-based rules to OCR output, images, videos, and documents. Custom patterns can target organization-specific identifiers, case numbers, or proprietary terms.
Document and Image Translation
OCR-Based Translation
Document and image translation requires OCR processing to be completed first. The workflow proceeds as follows:
- OCR extracts text into blocks, preserving position and layout
- Text blocks are input to LLMs for translation into target languages
- Translated content is regenerated into original file formats (PDF, PNG) while maintaining styling and positioning
Summary
VIDIZMO AI content processing combines modular AI workflows, dependency aware orchestration, and reusable artifacts to deliver scalable and reliable multimedia intelligence. By separating visual, audio, language, and LLM-based workflows, VIDIZMO ensures efficient execution while enabling advanced capabilities such as redaction, summarization, translation, and compliance enforcement across content types.
Read Next
- Understanding Chaptering in VIDIZMO
- Understanding VIDIZMO OCR
- Translating Documents and Images using VIDIZMO Indexer
- Understanding Summarization in VIDIZMO